1 Something Big Is Happening
On the morning of February 9, 2026, Matt Shumer sat in front of a laptop and opened a conversation with Claude.
Shumer was twenty-six. A Syracuse grad who’d dropped out of a management program to build AI tools, he’d founded three companies before most people his age had finished their first performance review — a healthcare VR startup that got acquired in two years, a direct-to-consumer brand, and OthersideAI, the company behind HyperWrite, an AI writing assistant with nearly two million users. He wasn’t a researcher. He wasn’t a policy person. He was a builder, and he’d spent the past three months watching the tools he built with become capable of building themselves.
He had something to say, and he asked an AI to help him say it.
Over the next several hours, Shumer worked with Claude — Anthropic’s large language model — to draft, restructure, and sharpen a 4,779-word essay. Later, he’d be transparent about the collaboration: “It did help a lot,” he told reporters, “and I think that’s kind of the point” (TBPN 2026). The essay was titled “Something Big Is Happening.” Its opening line cut straight to the point: something unprecedented was unfolding in artificial intelligence, and most people had not yet grasped the scale of it (Shumer 2026). Within seventy-two hours, it would be read more than fifty million times.
The timing was not accidental. Four days earlier, on February 5, two events had landed simultaneously that sent shockwaves through global markets. Anthropic released Claude Opus 4.6, a model capable of orchestrating teams of AI agents, processing up to one million tokens of context, and integrating directly with office productivity software (Anthropic 2026). On the same day, OpenAI released GPT-5.3-Codex — and quietly disclosed that the model had played a significant role in its own development, having been used to debug its own training runs, manage its own deployment, and diagnose its own evaluations (OpenAI 2026).
The stock market’s reaction was immediate and brutal. By February 4, global software stocks had already begun plunging on fears that AI would disrupt the SaaS business model entirely (CNBC 2026). The selloff was not confined to speculative AI plays or small-cap names. Enterprise software giants — companies that had defined the cloud computing era — saw their valuations crater as investors rapidly repriced an entire sector’s future. The logic was simple and devastating: if an AI model could resolve nearly 80% of real-world software engineering tasks, and if another model had contributed to its own development, then the business model of selling human-productivity software was facing an existential question. Between February 3 and February 6, roughly two trillion dollars evaporated from software stocks alone — the largest non-recessionary twelve-month drawdown in over thirty years, slashing the sector’s weight in the S&P 500 from 12.0% to 8.4% (Fortune 2026b). ServiceNow fell 7.6% in a single session. Intuit dropped 11%. Thomson Reuters had its worst day on record, down 16%, as traders priced in a future where AI could draft legal documents faster and cheaper than the platform’s human subscribers (Fortune 2026a). The causes were inverted from every previous tech crash — this one was driven not by the failure of technology to deliver on its promises, but by its success.
It was into this atmosphere — markets in freefall, two of the most powerful AI systems ever built freshly released, and a growing sense of vertigo among technologists — that Shumer published his essay.
1.2 Why It Resonated
None of this was new information. Every data point Shumer cited was already public. What he did — and what explained the essay’s extraordinary reach — was assemble those data points into a single, coherent narrative at precisely the moment when millions of people were searching for one.
Consider what had happened in the preceding weeks and months:
- January 22, 2026: NVIDIA forecast $65 billion in quarterly revenue, reflecting what CEO Jensen Huang called insatiable demand for AI chips, with $500 billion in visibility for Blackwell and Rubin chip revenue (The Motley Fool 2026).
- January 27, 2026: Dario Amodei, CEO of Anthropic, published a 20,000-word essay titled “The Adolescence of Technology,” warning that AI would “test who we are as a species” and predicting “a country of geniuses in a datacenter” within a few years (Amodei 2026).
- January 27, 2026: At the World Economic Forum in Davos, Amodei publicly predicted that AI would replace most software engineers’ work within six to twelve months, sparking a heated debate with Google DeepMind CEO Demis Hassabis (Business World 2026).
- February 4–6, 2026: The combined release of Claude Opus 4.6 and GPT-5.3-Codex triggered a trillion-dollar market selloff (Fortune 2026a; CNBC 2026).
Shumer’s essay arrived as the capstone on a month of escalating signals. It gave ordinary readers — people who did not follow AI benchmarks or read corporate earnings calls — a framework for understanding why their social media feeds were suddenly full of panic.
By early February 2026, the public mood had curdled into something between confusion and dread. Surveys showed that worker concerns about AI-driven job loss had jumped from 28% in 2024 to 40% by early 2026 (Harvard Business Review 2026). But those numbers understated the anxiety. The people who were not yet worried were, in many cases, simply not paying attention. Those who were paying attention — software engineers watching SWE-bench scores climb past 79%, customer support managers watching Salesforce cut 4,000 positions, junior analysts watching their tasks get routed to AI agents — were experiencing something closer to dread (Challenger, Gray & Christmas 2025; Epoch AI 2025). The Harvard Business Review noted in January 2026 that companies were laying off workers based on AI’s potential, not its demonstrated performance — a sign that the narrative itself had become an economic force (Harvard Business Review 2026).
Shumer’s essay cut through the noise because it refused to hedge. Where corporate communications couched AI progress in careful language about “augmentation” and “human-AI collaboration,” Shumer stated plainly that nothing done on a computer was safe. Where policy discussions moved at the pace of committee schedules, he wrote with the urgency of someone watching a building catch fire. The essay spread across X, LinkedIn, Reddit, and mainstream outlets within hours of publication. Technology journalists who had been covering AI incrementally — one benchmark, one product launch, one earnings call at a time — suddenly had a single document that connected all the threads. It was not that Shumer had said anything that insiders did not already know. It was that he had said it all at once, in plain language, at the exact moment when millions of people were ready to hear it. And he closed with a line that readers repeated more than any other — three short sentences that functioned less as a conclusion than as a warning:
“The future is already here. It just hasn’t knocked on your door yet. It’s about to.” (Shumer 2026)
For the LinkedIn managers and the recent graduates and the engineers watching their benchmarks climb, that final line landed not as rhetoric but as a statement of fact they could no longer afford to ignore.
1.3 The November Precedent
The February 2026 releases that precipitated Shumer’s essay — Claude Opus 4.6 on February 5, GPT-5.3-Codex on the same day — commanded the headlines. But to locate the real inflection point in February is to mistake the confirmation for the cause. The shift had already happened, and it happened in the span of twenty-four days during November and December 2025.
On November 17, 2025, xAI released Grok 4.1, a model that achieved 1,483 Elo on LMArena’s Text Arena in its thinking mode — the highest score recorded to that date — while reducing its hallucination rate by 65% compared to its predecessor (xAI 2025). The release was notable less for any single metric than for what it signaled about the pace of competition. xAI, a company that had been dismissed by many as a vanity project, was now producing models that outperformed the established frontier labs on multiple dimensions. The playing field was widening at the exact moment the models themselves were getting dramatically better.
The next day, November 18, Google DeepMind released Gemini 3. The model scored 1,501 Elo on LMArena, immediately surpassing Grok 4.1’s record (Google DeepMind 2025b). On SWE-bench Verified, Gemini 3 Pro achieved 77.4% when paired with an agentic scaffolding — a score that would have been considered science fiction twelve months earlier (Epoch AI 2025). Gemini 3 represented a generation-level leap over Gemini 2.5, arriving less than six months after Gemini 2.5 had itself been positioned as a major advance.
Six days later, on November 24, 2025, Anthropic released Claude Opus 4.5. Where Gemini 3 had dominated the general-purpose leaderboard, Opus 4.5 staked its claim on the metric that mattered most for the automation debate: it scored 79.2% on SWE-bench Verified, surpassing Gemini 3 Pro and setting a new ceiling for AI software engineering capability (Epoch AI 2025). METR’s evaluation measured Opus 4.5’s autonomous time horizon at 4 hours and 49 minutes — meaning the model could sustain effective, independent work for nearly half a standard workday (Greenblatt 2025). The model could take on the kind of sustained, complex work that defined a mid-level engineer’s daily output.
On December 4, Google DeepMind rolled out Gemini 3 Deep Think, a reasoning-specialized variant that achieved gold-medal performance on the 2025 International Math Olympiad, scored 93.8% on GPQA Diamond (a graduate-level science reasoning benchmark), and reached 41.0% on Humanity’s Last Exam — a test explicitly designed to be beyond the reach of current AI (Google DeepMind 2025a). If Gemini 3 had demonstrated broad capability, Deep Think demonstrated depth: the ability to engage in sustained, rigorous reasoning at the level of the world’s best graduate students and beyond.
A week later, on December 11, OpenAI released GPT-5.2, offered in three variants — Instant, Thinking, and Pro — with a 400,000-token context window and significantly extended capabilities for long-duration tasks (OpenAI 2025). The release also included GPT-5.1 Codex-Max, an extended-compute variant specifically optimized for software engineering that pushed the boundaries of what agentic coding systems could accomplish.
The significance of these twenty-four days cannot be overstated. In less than a month, four organizations released five models that collectively redefined what AI could do. SWE-bench scores went from the low 70s to nearly 80%. Autonomous task duration jumped from roughly two hours to nearly five. Reasoning benchmarks that had been designed as multi-year challenges were cleared in months. And critically, each release built competitive pressure for the next, creating a dynamic where no lab could afford to hold back capabilities for further safety testing or gradual rollout.
This was the real inflection point — not February 2026, but November-December 2025. What happened in February was a confirmation and an amplification: the dual release of Opus 4.6 and GPT-5.3-Codex confirmed that the pace was not slowing, and the market’s trillion-dollar reaction amplified the signal to the general public. But the shift itself — the moment when AI capability crossed from impressive demonstration to practical threat — had already occurred. By the time Shumer sat down to write his essay, he was not predicting the future. He was documenting a transformation that had unfolded over the preceding ten weeks.
Simon Willison, the veteran software developer and technology writer, captured the significance of this period in his analysis of the StrongDM software factory. He noted that “Claude Opus 4.5 and GPT-5.2 appeared to turn the corner on how reliably a coding agent could follow instructions” — a characterization that, while understated, pointed to the qualitative difference between the models of early 2025 and those of late 2025 (Willison 2026). The models had not simply gotten better at the same tasks. They had become reliable enough to be trusted with tasks that no one would have previously delegated to an AI system. That is not an incremental improvement. That is a phase transition.
1.4 The Confirmation Gap
This book proposes a name for the pattern we’ve just described: the Confirmation Gap.
The Confirmation Gap is the interval between the moment a technology crosses a threshold of practical capability and the moment the broader public recognizes that crossing. It is not the same as a hype cycle, where excitement precedes delivery. It is the opposite: delivery precedes recognition. The capability arrives first. The understanding arrives later. And in the space between, decisions get made — hiring freezes, market repricing, policy responses — based on incomplete awareness of a shift that has already occurred.
In the case of AI, the Confirmation Gap looked like this:
- Capability inflection: November 17 through December 11, 2025. Five frontier models ship. SWE-bench hits 79.2%. Autonomous task duration reaches five hours. The technology crosses from impressive demonstration to practical substitute for categories of human work.
- Behavioral proof: December 2025 through January 2026. Engineering teams restructure. Startups slash headcount. Anthropic’s own engineers begin shipping code that is 100% AI-generated. The changes happen inside companies, invisible to the public.
- Public confirmation: February 5, 2026. Claude Opus 4.6 and GPT-5.3-Codex launch. Markets crash. Shumer publishes. Fifty million people read the essay. The world catches up to what practitioners have known for ten weeks.
The Confirmation Gap matters because it determines who adapts early and who gets blindsided. The engineers who used Opus 4.5 in December had three months’ head start on the LinkedIn managers who read Shumer’s essay in February. The investors who tracked METR’s time-horizon data repositioned their portfolios before the selloff. The companies that began restructuring around AI agents in January were hiring while their competitors were still debating whether AI was real.
This book traces the Confirmation Gap from its opening in November 2025 through its narrowing in February 2026, and asks whether the pattern will repeat — or whether, the next time capability leaps ahead, the gap will close fast enough for institutions to respond before the consequences arrive.
1.5 The Predictions, Broken Down
To understand why Shumer’s essay mattered, it helps to look at each of its major predictions in the context of the evidence that already existed by February 2026. This book tracks twenty-three specific predictions from Shumer and other prominent figures. Here, we introduce the five that formed the backbone of the essay.
1.5.1 1. The Recursive Improvement Loop
Shumer’s central thesis was that AI had entered a self-reinforcing cycle: better models enable better tools for building models, which produce still better models. The strongest piece of evidence was GPT-5.3-Codex, which OpenAI disclosed had contributed substantially to its own development process (OpenAI 2026).
By February 2026, our analysis estimates this prediction was approximately 95% realized. The model had been used during its own training to debug code, manage deployment pipelines, and diagnose evaluation failures. While this fell short of full autonomous self-improvement — human researchers still set the objectives and architecture — it marked a clear inflection point.
1.5.2 2. Software Engineering Under Threat
On the SWE-bench Verified benchmark, which measures an AI system’s ability to resolve real-world GitHub issues, scores had risen from 2.7% for GPT-4 with RAG in early 2024 to 79.2% for Claude Opus 4.5 by late 2025 (Epoch AI 2025). By the time Shumer wrote his essay, two models — Claude Opus 4.5 and Claude Opus 4.6 — were resolving nearly four out of every five verified software engineering tasks thrown at them.
The implication was stark. If an AI system could resolve 79% of real-world software bugs drawn from production codebases, then a significant fraction of entry-level and mid-level software engineering work was already automatable.
1.5.3 3. Job Displacement Is Already Happening
By February 2026, the numbers told a clear story. Hundreds of thousands of technology workers had been laid off across 2024 and 2025, with a significant and growing share of those cuts directly attributed to AI automation (Challenger, Gray & Christmas 2025; CNBC 2025b). Worker concerns about AI job loss had jumped from 28% in 2024 to 40% by early 2026 (Harvard Business Review 2026). The full scope of the displacement is examined in Chapter 6.
Shumer was not predicting job displacement; he was documenting it.
1.5.4 4. Autonomous AI Duration Is Growing Exponentially
The organization METR (Model Evaluation and Threat Research) had been tracking how long AI systems could work autonomously on complex tasks. Their data showed an exponential curve: from roughly 2 minutes in 2019 (the GPT-2 era) to nearly 5 hours by late 2025 (Claude Opus 4.5, measured at 4 hours and 49 minutes) (METR 2025; Greenblatt 2025).
The doubling time was approximately seven months, and there were signs it was accelerating to as little as four months during the 2024–2025 period. If the trend continued, AI systems would be capable of 32 hours of autonomous work by mid-2027 — implying they could take on tasks that currently required a human working for an entire week.
1.5.5 5. This Is Bigger Than Covid
Shumer’s most provocative comparison was to the Covid-19 pandemic. His argument: Covid had disrupted physical commerce and accelerated digital transformation, but it left the nature of digital work largely intact. AI, by contrast, was coming for digital work itself. Trillion-dollar market shifts, hundreds of thousands of layoffs, policy upheaval across governments — the impact was already massive, and Shumer argued it was just beginning (Shumer 2026).
By our assessment, this prediction was approximately 30% realized by February 2026. The market disruption, job losses, and policy responses were real and significant. But the full societal restructuring that Shumer envisioned — comparable to how Covid reshaped daily life for billions — was still unfolding.
This book tracks twenty-three specific predictions made by technology leaders between 2024 and early 2026. Figure 1.1 provides an overview of where those predictions stood as of February 12, 2026.
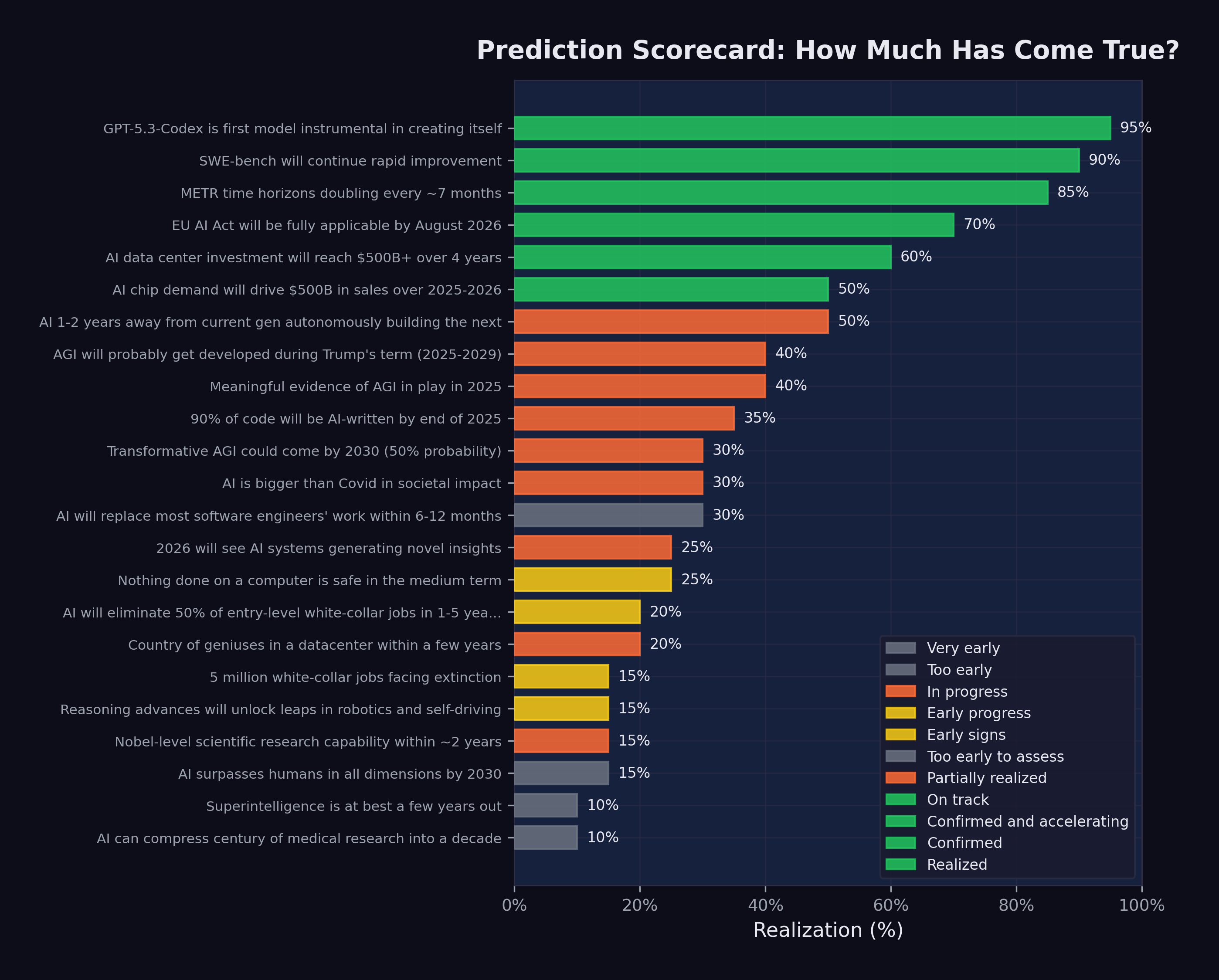
The scorecard reveals a clear pattern. Predictions related to technical benchmarks and capability metrics — SWE-bench scores, METR time horizons, model self-improvement — were being confirmed or exceeded ahead of schedule. Predictions related to broader societal impacts — job displacement at scale, AGI timelines, superintelligence — showed early signs but remained further from full realization. And predictions about regulatory response, particularly the EU AI Act timeline, were proceeding largely on schedule.
This asymmetry is itself revealing. The technology is moving faster than most predicted. The societal response is moving roughly as expected. And the gap between the two — between what AI can do and what institutions are prepared for — is where the real story lies.
Of the twenty-three predictions tracked in this book, the distribution as of February 12, 2026, was as follows: seven were scored at 50% realization or above, meaning they were substantially confirmed or well on track. Ten were scored between 20% and 49%, meaning early evidence supported them but full realization remained ahead. Six were scored below 20%, meaning they were either too early to assess or showing minimal progress.
The predictions that scored highest — the recursive improvement loop (95%), SWE-bench crossing 80% (90%), and the 90% AI-coded threshold at Anthropic (35%) — shared a common characteristic: they were specific, measurable, and focused on what was happening inside AI laboratories rather than across the broader economy. The predictions that scored lowest — superintelligence within years (10%), AI compressing a century of medical research (10%), and humanoid robotics breakthroughs (15%) — required either systemic societal change or breakthroughs in domains where AI’s advantages are less pronounced.
This pattern suggests a useful heuristic for evaluating AI predictions. Claims about what happens inside the lab tend to be accurate or even conservative. Claims about what happens when the technology meets the full complexity of human institutions tend to be premature. The technology itself is not the bottleneck. Adoption, regulation, organizational change, and the messy, slow process of restructuring entire industries — these are the bottlenecks. The people building AI systems are, by and large, correctly forecasting what those systems will be able to do. They are less accurate at forecasting how quickly the world will reorganize itself around those capabilities.
There is one additional pattern worth noting. Several predictions made by different people in different contexts turned out to describe the same underlying phenomenon. Amodei’s warning about recursive self-improvement, Shumer’s observation about the self-reinforcing loop, and OpenAI’s disclosure that GPT-5.3-Codex had contributed to its own development were three framings of a single reality (Amodei 2026; Shumer 2026; OpenAI 2026). Similarly, Amodei’s prediction of 50% entry-level job loss and Microsoft Research’s identification of five million vulnerable positions were two calibrations of the same displacement dynamic (Amodei 2025; CNBC 2025a). The convergence of independent predictions onto common phenomena is a stronger signal than any individual prediction. When people with different data, different incentives, and different methodologies arrive at the same conclusion, the conclusion deserves serious attention.
1.6 The Case Against
Not everyone bought it.
Within days of Shumer’s essay going viral, a counter-narrative took shape — sharper, more specific, and backed by people with credentials that demanded attention. Gary Marcus, the NYU emeritus professor who’d built a career as AI’s most rigorous skeptic, published a detailed rebuttal. His verdict was blunt: Shumer’s essay contained “not a shred of actual data” (Marcus 2026). Marcus pointed out that when Shumer cited METR’s time-horizon benchmark as evidence of exponential AI capability, he neglected to mention that the benchmark’s success criterion was 50% correct — not 100%. A system that completes half of its tasks correctly isn’t autonomous. It’s a coin flip with extra steps.
Jeremy Kahn, Fortune’s AI editor, published a longer dissection. His central argument: software development is a uniquely automatable domain because code has objective quality metrics — it compiles or it doesn’t, tests pass or they fail. Most professional work has no equivalent. “There are no compilers for law,” Kahn wrote, “no unit tests for a medical treatment plan” (Kahn 2026). He noted that even OpenAI’s own GDPval benchmark showed human experts agreeing on AI output quality only 71% of the time. Most companies, Kahn argued, “cannot tolerate the possibility that poor quality work is being shipped in a third of cases.”
Vishal Misra, vice dean at Columbia University, offered a different frame. “The camera didn’t kill painting,” he wrote on X. “It liberated it” (Business Insider 2026). The historical argument: every technology that automated one category of work created new categories that hadn’t existed before. ATMs didn’t eliminate bank tellers; they freed them for advisory roles. Excel didn’t eliminate accountants; it turned them into analysts. Why should AI be different?
These objections weren’t trivial. They pointed to real limitations in Shumer’s argument: the extrapolation from software benchmarks to all knowledge work, the omission of reliability thresholds, the assumption that benchmark performance translates directly to economic disruption. A book committed to evidence must take them seriously.
Here are the conditions under which the core thesis of this book would be wrong:
- Benchmark plateau. If SWE-bench Verified scores stall below 90% through 2027, it suggests the current scaling paradigm has hit diminishing returns for practical software engineering — and extrapolation to other domains is premature.
- Adoption stall. If AI-attributed job displacement doesn’t exceed 5% of knowledge-worker employment by end of 2027, the “already happened” framing overstates the pace of institutional change.
- The historical pattern holds. If, by 2028, new job categories created by AI exceed the positions it eliminated — as ATMs and spreadsheets did before — the net disruption narrative was wrong, even if the gross displacement was real.
We’ll revisit these conditions in Chapter 14. For now, note the asymmetry: the critics aren’t arguing that AI hasn’t improved. They’re arguing that improvement on benchmarks doesn’t automatically translate to improvement in the messy, regulated, liability-laden world where actual work gets done. That’s a meaningful distinction, and the evidence will settle it. This book is designed to track that evidence.
1.7 Who Was Saying These Things?
Shumer was far from alone. His essay drew on, and amplified, warnings that had been building from some of the most powerful figures in the AI industry. Dario Amodei at Anthropic. Sam Altman at OpenAI. Demis Hassabis at Google DeepMind. Jensen Huang at NVIDIA. Researchers at Microsoft, METR, and Stanford.
Each brought a different perspective. Each had different incentives. Some were selling products. Some were seeking regulation. Some were genuinely alarmed. But they were all saying versions of the same thing: something big was happening, and it was happening faster than anyone had planned for.
In the next chapter, we examine what each of these voices was saying, when they said it, and how their predictions have held up against reality.
1.8 What This Book Does
This is not a book of predictions. There are enough of those already. This is a book of documentation — an attempt to record, with precision and primary sources, the moment when artificial intelligence stopped being a technology that might change the world and became a technology that was actively changing it.
Our methodology is straightforward. We track specific, falsifiable predictions made by identified individuals or organizations, each with its original date and source. For each prediction, we gather the best available evidence of its realization as of our snapshot date of February 12, 2026. We score each prediction on a realization scale from 0% (no evidence of progress) to 100% (fully confirmed), with our reasoning documented and our data publicly available. Where the evidence is ambiguous, we say so. Where our assessment is necessarily subjective — as it must be for predictions about societal transformation rather than benchmark scores — we explain the basis for our judgment.
Every claim in this book is tied to a primary source: an official announcement, a published essay, a benchmark report, a financial filing, or a credible news account. Where we rely on secondary sources, we note it. Where quotes could not be independently verified, we flag them. The full bibliography, data files, and scoring methodology are available in the project’s open-source repository, and we invite scrutiny.
The timestamps matter. In December 2024, Sam Altman wrote on his blog: “We are now confident we know how to build AGI” (Altman 2024). In a field moving this quickly, the difference between a prediction made in March 2025 and one made in November 2025 is the difference between foresight and observation. We are precise about dates because the chronology is itself part of the story. When Dario Amodei predicted in May 2025 that AI would write 90% of code by end of year, that was a bold forecast. When the same claim was confirmed six months later, it was a data point. This book tracks the transition from one to the other.
We also track what did not happen. Several predictions included in our scorecard showed minimal realization by February 2026. Humanoid robotics did not achieve the breakthroughs some predicted. AI-driven medical research, while promising, had not yet compressed decades into years. Superintelligence remained a theoretical projection rather than an observed reality. These misses and delays are as important to document as the hits, because they reveal where the technology’s actual trajectory diverges from the narrative.
1.9 Reading This Book
The book is organized in five parts across fourteen chapters, designed to be read sequentially but also to function as standalone references.
Part I: The Predictions (Chapters 1–2) establishes the context. This chapter — the one you are reading now — documents the essay that crystallized the moment, the events that preceded it, and the twenty-three predictions that form the book’s analytical backbone. Chapter 2 examines the voices that issued these predictions: the CEOs, researchers, and builders who warned, with varying degrees of urgency and specificity, about what was coming.
Part II: The Evidence (Chapters 3–6) presents the data. Chapter 3 is the authoritative treatment of SWE-bench and coding benchmarks — the numbers that made the abstract concrete. Chapter 4 examines METR’s autonomous time horizon data, which tracks how long AI systems can work without human intervention. Chapter 5 surveys the flood of model releases: twenty-eight major models in just over two years, each pushing the frontier further. Chapter 6 examines the human cost — the layoffs, the restructurings, and the emerging shape of a post-AI workforce.
Part III: The Inflection (Chapters 7–10) traces the transformation. Chapter 7 follows the recursive improvement loop from theory to practice, centering on the moment when GPT-5.3-Codex became the first model to contribute substantially to its own development. Chapter 8 argues for the November thesis — that the real inflection point was not February 2026 but the twenty-four days between November 17 and December 11, 2025, when five frontier models shipped from four organizations. Chapter 9 examines the emerging software factory model, from StrongDM’s dark factory to Dan Shapiro’s five levels of AI-assisted development. Chapter 10 documents the compounding teams — organizations that have restructured their entire workflow around AI, achieving exponential rather than linear productivity gains.
Part IV: The Broader Impact (Chapters 11–12) maps the wider consequences. Chapter 11 traces the investment tsunami — over $700 billion committed to AI infrastructure in a single year. Chapter 12 examines the geopolitical chessboard: American speed, European regulation, and Chinese efficiency as competing strategies for AI dominance.
Part V: What Comes Next (Chapters 13–14) looks forward. Chapter 13 assesses the science acceleration — where AI is transforming research across domains from mathematics to drug discovery, and where physical bottlenecks remain. Chapter 14 presents the full prediction scorecard, analyzes the patterns that emerge, and asks the question the title of this book insists upon: if something big has already happened, what do we do now?
Each chapter can be read independently, but the cumulative effect is intentional. The purpose of this book is not to alarm or reassure. It is to document, as faithfully as we can, what happened, when it happened, and what it meant — so that when the future arrives, there will be an honest record of the moment we saw it coming.
Throughout this book, we rely on primary sources wherever possible: published essays, earnings calls, benchmark reports, and official announcements. All predictions are tracked with their original date, source, and our assessment of their realization as of February 2026. The full methodology and data are available in the project’s open-source repository.
But first: Who were the people making these predictions? What did they know, when did they know it, and why should anyone believe them? The answer begins in the offices, conference stages, and blog posts of the people who built the systems that changed everything — and the ones who warned us, with varying degrees of accuracy, about what was coming.